本周工作#
实验补充#
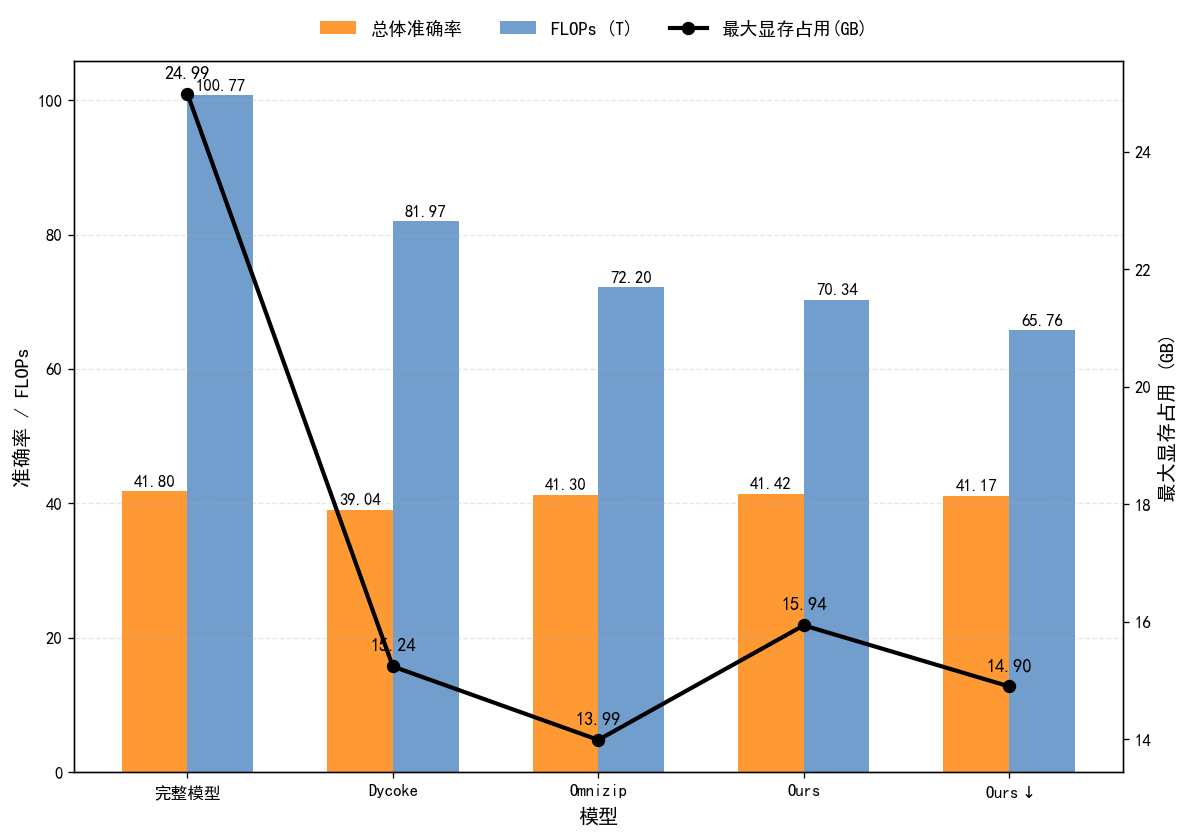
| 模型 | 最大显存占用(GB) | FLOPs(T) | 总体准确率 |
|---|---|---|---|
| 完整模型 | 24.99 | 100.77 | 41.80 |
| Dycoke | 15.24 | 81.97 | 39.04 |
| Omnizip | 13.99 | 72.20 | 41.30 |
| Ours | 15.94 | 70.34 | 41.42 |
| Ours⬇ | 14.90 | 65.76 | 41.17 |
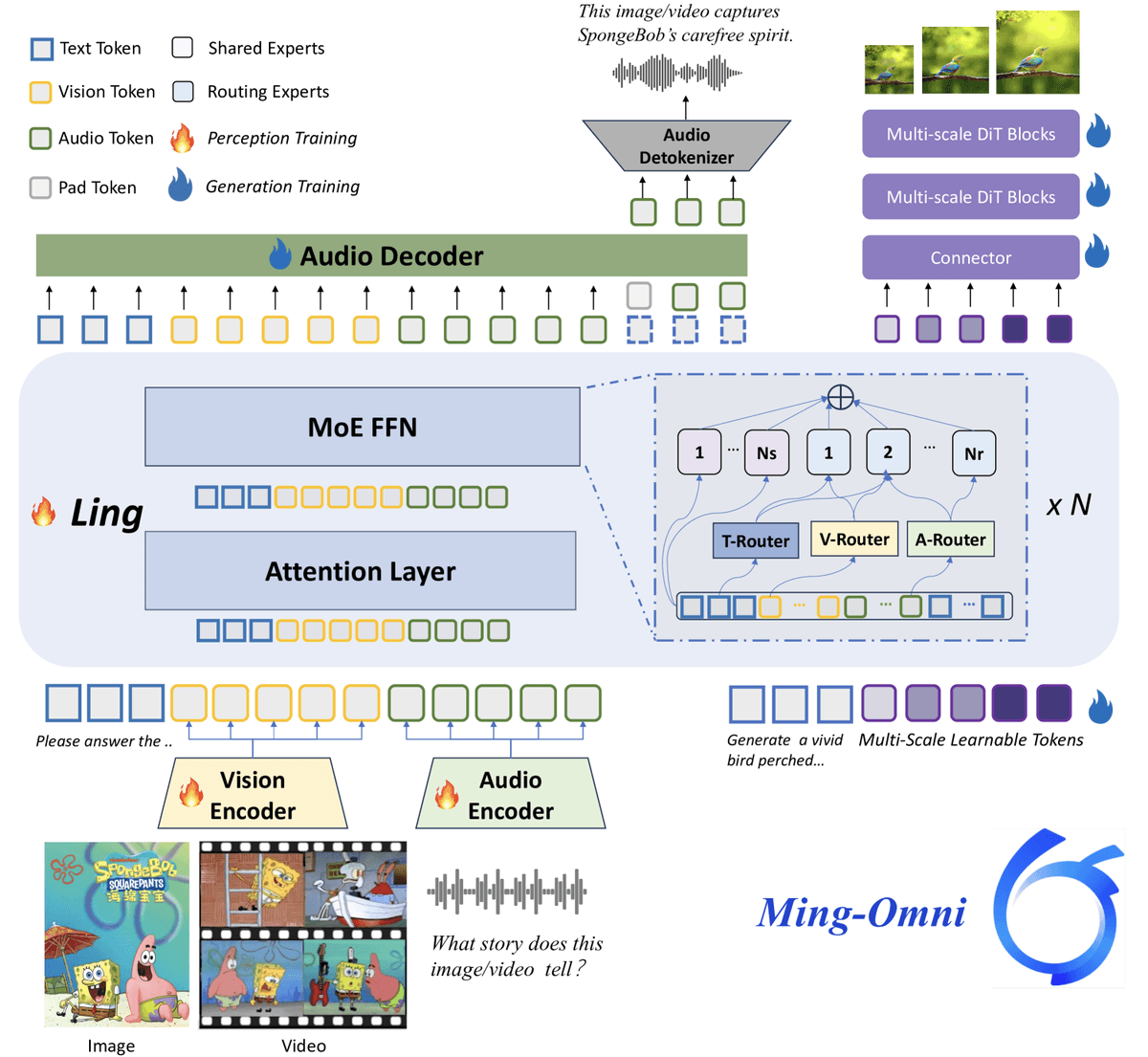
自适应选择 LLM 内部剪枝层#
用少量样本统计相邻层音视频 token hidden state 的平均余弦相似度,将 作为变化强度 。通过阈值找到第一个波动区间,并在其后寻找 连续多层维持低值的平静区间 。在平静区间内,选择音视频 token 作为 Key 接收注意力达到一定阈值的最早层作为 LLM 内部剪枝层。
变化强度#
对第 层到 层,相邻层变化强度定义为
- 表示音频+视频 token 的集合
- 越大,说明这一层变化更剧烈。图里“余弦更低/低于阈值更多”的层就对应 的峰。
用 配合阈值来确定寻找发生显著变化的层,定义为波动区间
平静区间:波动区间之后, 连续 (=3)层都低于一个稳定阈值 :
音视频 token 收到的注意力较高#
音视频 token 作为 K 被看得多
- 是所有 query token
- 是对 head 平均后的 attention。
最终选层#
先得到平静区间 ,选平静区间内最早满足注意力阈值的最早层
在其他多模态模型上#
在其他多模态模型上试验自适应的选层方法,目前找了两个模型;测试了其完整模型的 worldsense 上的准确率
| Model | Worldsense |
|---|---|
| Qwen2.5-omni7B(Omnizip) | 46.80 |
| Ming-Omni | 未报告 |
| 复现 | 46.44 |
9B
| Model | Worldsense |
|---|---|
| Qwen2.5-omni7B(Omnizip) | 46.80 |
| Qwen2.5-Omni7B(OmniVinci) | 45.40 |
| OmniVinci | 48.23 |
| 复现 | 47.56 |
复现是用的 OmniVinci 模型然后套用的 Omnizip 在 worldsense 上的评估的代码
这个还没提 issue 问,打算要一下评估代码
后续计划#
-
在这些模型上做类似分析(注意力,token 变化)
-
在进入 llm 之前交叉注意力?
补充#
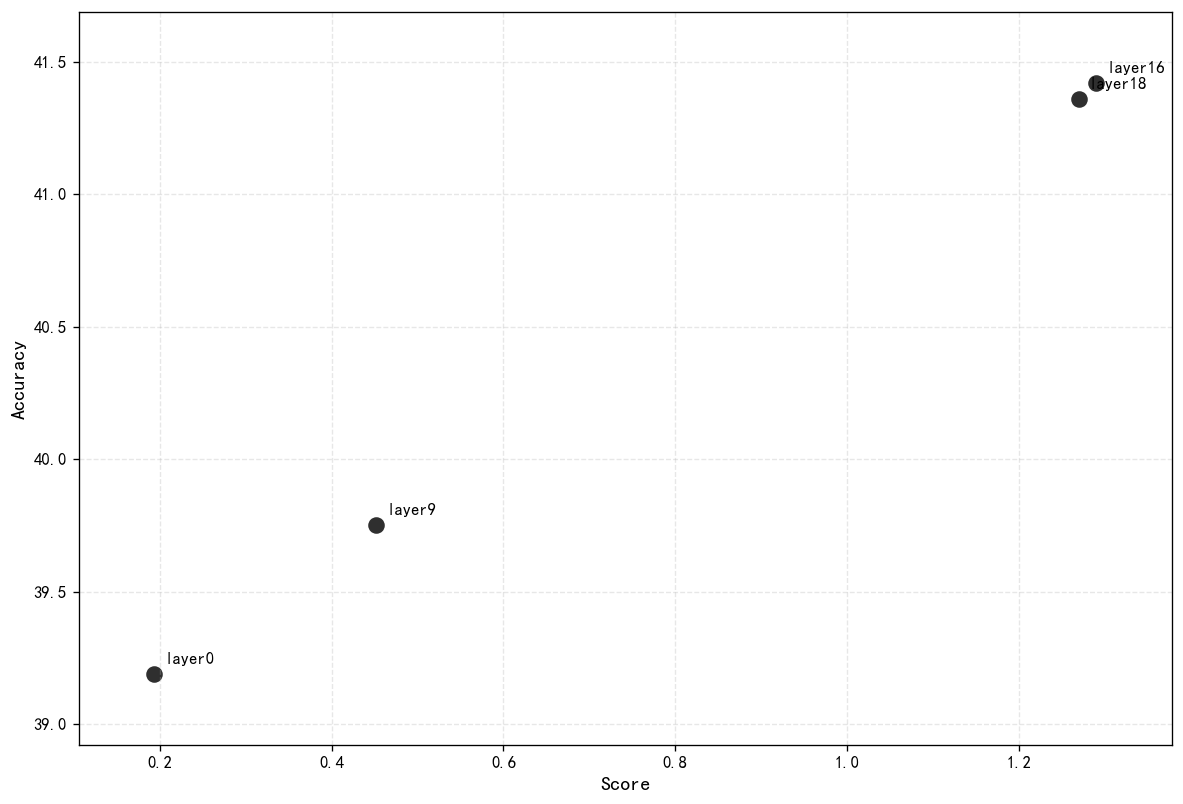
| layers | FLOPs(T) | overall_accuracy |
|---|---|---|
| 0 | 62.37 | 39.19 |
| 9 | 66.85 | 39.75 |
| 16 | 70.34 | 41.42 |
| 18 | 71.33 | 41.36 |
-
稳定度
对每一层 ,分别在视频 token 与音频 token 上计算相邻层 hidden state 的平均余弦相似度:
其中 分别为当前样本中的视频/音频 token 索引集合。定义融合变化强度:
设置窗口大小为 ,对每层定义局部变化均值:
那稳定度就是:
对 做 min-max 归一化得到 。
-
注意力强度
第 层注意力权重:统计音频/视频 token 作为 Key 被分配的注意力质量,并按 token 数归一化,将两者相加并做 min-max 归一化得到:
给定权重系数 ,基础分数定义为:
都是 1,没调整过
-
其他
设阈值为 , 取 的分位数( 取的 0.75)
变化起点为第一个满足 的层:
抑制信息融合之前层的得分,并鼓励在融合后的稳定区域选层,引入分段权重
线性的,r 是步长(想要表示变化区间长度),这里实现还不是很完善,我这里是固定的一个步长大小,如果检测到稳定区间开始来设置动态步长应该更好点;或者最大值不给到 1,而是给到 0.5 这种,确保变化的时候不容易被选中
考虑到融合后越早剪枝越省 FLOPs,在开始融合后引入指数衰减的早期加成,倾向于选中更早的层:
最终分数为:
选择得分最高的层作为内部剪枝层:
<!-- Overall Accuracy: 0.4600 (1459/3172) -->
CUDA_VISIBLE_DEVICES=1,7 nohup python omnizip_eval.py --WAPPER-METHOD full > full_model.log 2>&1 &
<!-- Overall Accuracy: 0.4537 (1439/3172) -->
CUDA_VISIBLE_DEVICES=2,3 nohup python omnizip_eval.py --WAPPER-METHOD omnizip --OMNIZIP_RHO_AUDIO 0.3 --OMNIZIP_RHO_VIDEO 0.6 --OMNIZIP_G 3 --OMNIZIP_CONTEXTUAL_RATIO 0.05 > omnizip.log 2>&1 &
<!-- Overall Accuracy: 0.4319 (1370/3172) -->
CUDA_VISIBLE_DEVICES=4,5 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 0 > ours0.log 2>&1 &
<!-- Overall Accuracy: 0.4366 (1385/3172) -->
CUDA_VISIBLE_DEVICES=0 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 1 > ours1.log 2>&1 &
<!-- Overall Accuracy: 0.4376 (1388/3172) -->
CUDA_VISIBLE_DEVICES=1 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 2 > ours2.log 2>&1 &
<!-- Overall Accuracy: 0.4385 (1391/3172) -->
CUDA_VISIBLE_DEVICES=1 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 3 > ours3.log 2>&1 &
<!-- Overall Accuracy: 0.4395 (1394/3172) -->
CUDA_VISIBLE_DEVICES=6,7 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 4 > ours4.log 2>&1 &
<!-- Overall Accuracy: 0.4379 (1389/3172) -->
CUDA_VISIBLE_DEVICES=2 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 5 > ours5.log 2>&1 &
<!-- Overall Accuracy: 0.4474 (1419/3172) -->
CUDA_VISIBLE_DEVICES=2 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 6 > ours6.log 2>&1 &
<!-- Overall Accuracy: 0.4366 (1385/3172) -->
CUDA_VISIBLE_DEVICES=3 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 7 > ours7.log 2>&1 &
<!-- Overall Accuracy: 0.4451 (1412/3172) -->
CUDA_VISIBLE_DEVICES=2,3 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 8 > ours8.log 2>&1 &
<!-- Overall Accuracy: 0.4388 (1392/3172) -->
CUDA_VISIBLE_DEVICES=4 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 9 > ours9.log 2>&1 &
<!-- Overall Accuracy: 0.4499 (1427/3172) -->
CUDA_VISIBLE_DEVICES=3 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 10 > ours10.log 2>&1 &
<!-- Overall Accuracy: 0.4467 (1417/3172) -->
CUDA_VISIBLE_DEVICES=5 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 11 > ours11.log 2>&1 &
<!-- Overall Accuracy: 0.4492 (1425/3172) -->
CUDA_VISIBLE_DEVICES=4,5 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 12 > ours12.log 2>&1 &
<!-- Overall Accuracy: 0.4521 (1434/3172) -->
CUDA_VISIBLE_DEVICES=6 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 13 > ours13.log 2>&1 &
<!-- Overall Accuracy: 0.4543 (1441/3172) -->
CUDA_VISIBLE_DEVICES=4 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 14 > ours14.log 2>&1 &
<!-- Overall Accuracy: 0.4555 (1445/3172) -->
CUDA_VISIBLE_DEVICES=7 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 15 > ours15.log 2>&1 &
<!-- Overall Accuracy: 0.4552 (1444/3172) -->
CUDA_VISIBLE_DEVICES=2 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 16 > ours16.log 2>&1 &
<!-- Overall Accuracy: 0.4533 (1438/3172) -->
CUDA_VISIBLE_DEVICES=0 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 17 > ours17.log 2>&1 &
<!-- Overall Accuracy: 0.4546 (1442/3172) -->
CUDA_VISIBLE_DEVICES=5 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 18 > ours18.log 2>&1 &
<!-- Overall Accuracy: 0.4565 (1448/3172) -->
CUDA_VISIBLE_DEVICES=1 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 19 > ours19.log 2>&1 &
<!-- Overall Accuracy: 0.4587 (1455/3172) -->
CUDA_VISIBLE_DEVICES=3 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 20 > ours20.log 2>&1 &
<!-- Overall Accuracy: 0.4565 (1448/3172) -->
CUDA_VISIBLE_DEVICES=2 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 21 > ours21.log 2>&1 &
<!-- Overall Accuracy: 0.4565 (1448/3172) -->
CUDA_VISIBLE_DEVICES=6 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 22 > ours22.log 2>&1 &
<!-- Overall Accuracy: 0.4600 (1459/3172) -->
CUDA_VISIBLE_DEVICES=3 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 23 > ours23.log 2>&1 &
<!-- Overall Accuracy: 0.4518 (1433/3172) -->
CUDA_VISIBLE_DEVICES=4 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 24 > ours24.log 2>&1 &
<!-- Overall Accuracy: 0.4571 (1450/3172) -->
CUDA_VISIBLE_DEVICES=4 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 25 > ours25.log 2>&1 &
<!-- Overall Accuracy: 0.4606 (1461/3172) -->
CUDA_VISIBLE_DEVICES=7 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 26 > ours26.log 2>&1 &
<!-- Overall Accuracy: 0.4568 (1449/3172) -->
CUDA_VISIBLE_DEVICES=5 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 27 > ours27.log 2>&1 &
<!-- Overall Accuracy: 0.4590 (1456/3172) -->
CUDA_VISIBLE_DEVICES=5 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 28 > ours28.log 2>&1 &
<!-- Overall Accuracy: 0.4574 (1451/3172) -->
CUDA_VISIBLE_DEVICES=6 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 29 > ours29.log 2>&1 &
<!-- Overall Accuracy: 0.4590 (1456/3172) -->
CUDA_VISIBLE_DEVICES=0 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 30 > ours30.log 2>&1 &
<!-- Overall Accuracy: 0.4584 (1454/3172) -->
CUDA_VISIBLE_DEVICES=7 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 31 > ours31.log 2>&1 &
<!-- Overall Accuracy: 0.4565 (1448/3172) -->
CUDA_VISIBLE_DEVICES=6 nohup python eval-llm.py --WAPPER-METHOD omnizip --LLM_KEEP_RATIO 0.5 --LLM_PRUNE_LAYER 32 > ours32.log 2>&1 &