VTimeLLM 论文阅读
VTimeLLM: Empower LLM to Grasp Video Moments——论文研读
VTimeLLM: Empower LLM to Grasp Video Moments#
VTimeLLM:赋能 LLM 理解视频时刻
后面会提到的 LongVALE 和 PU-VALOR 都是基于这个代码库改写的, 但是似乎相承的是一套不怎么先进的代码 desewa
这篇论文是 LLM 到多模态的一个比较典型的论文, 三阶段训练微调, 因为主要看的最新的那个 LongVALE, 我只简单的过了一下这一篇
任务定义#
细粒度视频理解:也就是视频片段和语义上下文的对齐
- 时序视频定位:给定文本输入, 识别相应的视频片段
- 密集视频描述(字幕生成, Caption):对未剪辑视频中所有事件进行时序视频定位和 caption
详细的说明在训练的时候会提到
模型架构#
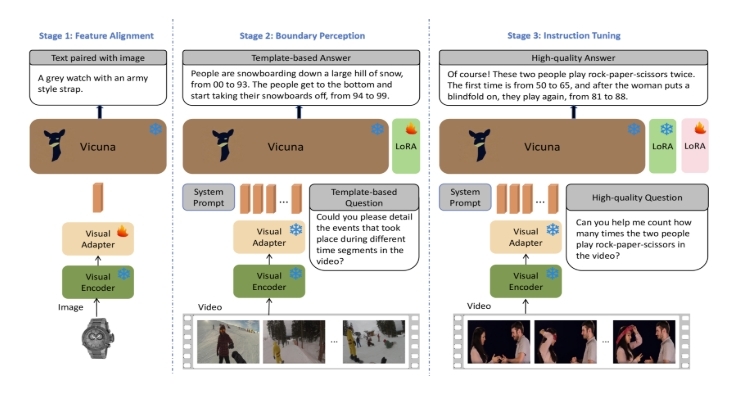
也就是在 LLM 基础上, 集成一个 visual encoder 和 ~ adapter, 把”视频 embedding”插入到 LLM 原本的 text embedding 中
实验的具体配置:
- LLM:Vicuna1.5-7B/13B
- Visual Encoder:CLIP-ViT-L/14 (用 cls_token 作为帧特征)
- Adapter: linear
流程#
输入视频 , 是视频的帧数, 是视频的高度, 是视频的宽度, 是视频的通道数;
均匀采样, N = 100, 取 100 帧, 有
因此帧索引的范围为 0~99, 在描述中使用 “从 s 到 e”, 表示从第 s 帧到第 e 帧
取每一帧的 cls_token 作为帧特征, 然后通过 linear adapter 映射到 LLM 维度
全部的视频帧经此处理, 有 , 由此, 我们得到了视频 embedding
用 <video> 标签插入到 LLM 输入中, 与文本 embedding 拼接起来, 作为 LLM 的输入。也即 , 其中 是文本 embedding, 为词数
边界感知三阶段训练框架#
1. 视觉特征对齐文本语义空间(LLM)#
-
数据集:
-
LLaVA 的 LCK-558 数据集(图像-文本对)
在这一步作者做了一次实验, 发现使用 Video-Text 数据(比如 WebVid 2M的一个子集)和混合二者的效果都不是很好;作者的解释是视频文本数据的话文本质量差, 存在视觉特征丢失
但是对于混合数据来说, 个人觉得不应该存在这个问题, 而且像 Qwen-omni 系列的模型也是混合数据训练的我记得, 或许和数据集质量有关系?
-
-
Training Strategy
- 只训练 Adapter 参数(其实现在通常在训练 Adapter 后还会反过来再训练一轮 Encoder), 其他冻结
2. 时间边界感知#
视频片段的语义理解, 确保和相应边界对齐(时序感知)
-
数据集
-
InternVid-10M-FLT(全自动视频片段分割、标注(时间描述, 大致时间戳))
T < 120s, 单个视频可能有多个非重叠事件标注, 每个事件长度大于 3s, 平均事件长度大于视频长度的 8%, 134K 个视频片段
-
-
任务:事件 ———— 对话数据 (提供了 10 个模板生成 Q/A, 附录), 按照对话类型划分为两类
-
20% 单轮对话 - 密集字幕生成
也就是输入 , 输出 : : from to ; : from to ;
-
80% 多轮对话 - 片段 caption + 时序视频定位
- 由 生成
- 由 生成
-
-
Training Strategy
- 需要在 propmt 中声明
<video>有 100 帧 - 只训练 LoRA (1), 其他冻结
- 需要在 propmt 中声明
3. 指令微调#
使用高质量的任务数据和 Chat 数据进行微调
为什么要指令微调? 论文中的解释是, 在 2 中, 由于过度关注 grounding 任务, 可能导致 chat 能力下降, 而且 2 中数据集质量一般(自动标注), 不准确且存在噪声
-
数据集(36k QA):
- 任务数据:(ActivityNet Captions 子集 + DiDeMo 子集) 16k QA
- Chat 数据(描述能力):VideoInstruct100K 20k QA
-
Training Strategy
- 只训练 LoRA (2), 其他冻结